LLM costs can be reduced 50–90% using five techniques — model routing, semantic caching, knowledge distillation, prompt compression, and quantization — without rewriting your application or accepting quality tradeoffs. Most enterprise AI spend goes to frontier models on tasks where a cheaper model produces identical results.
Engineering teams ship fast by reaching for their most capable model: GPT-4, Claude Opus, Gemini Ultra. The first call works. The pattern sticks. Six months later, you're routing classification tasks, simple summarizations, and JSON extraction through a frontier model that costs $15 per million output tokens — when a purpose-built alternative would cost $0.40/M and produce identical results on your specific workload.
Research puts the waste at 50–90% of total inference spend (Chen et al., Stanford — FrugalGPT, 2023). This article explains why it happens, what the academic literature says about fixing it, and how each technique stacks up in production.
Definition
LLM cost optimization is the practice of reducing AI inference expenditure without degrading output quality. It encompasses model routing (directing each query to the cheapest capable model), semantic caching (reusing prior responses for similar queries), knowledge distillation (training compact task-specific models), prompt compression (reducing token count), and quantization (reducing model weight precision). The goal is to pay for the intelligence each task actually requires — not the maximum available.
How to Reduce LLM Costs
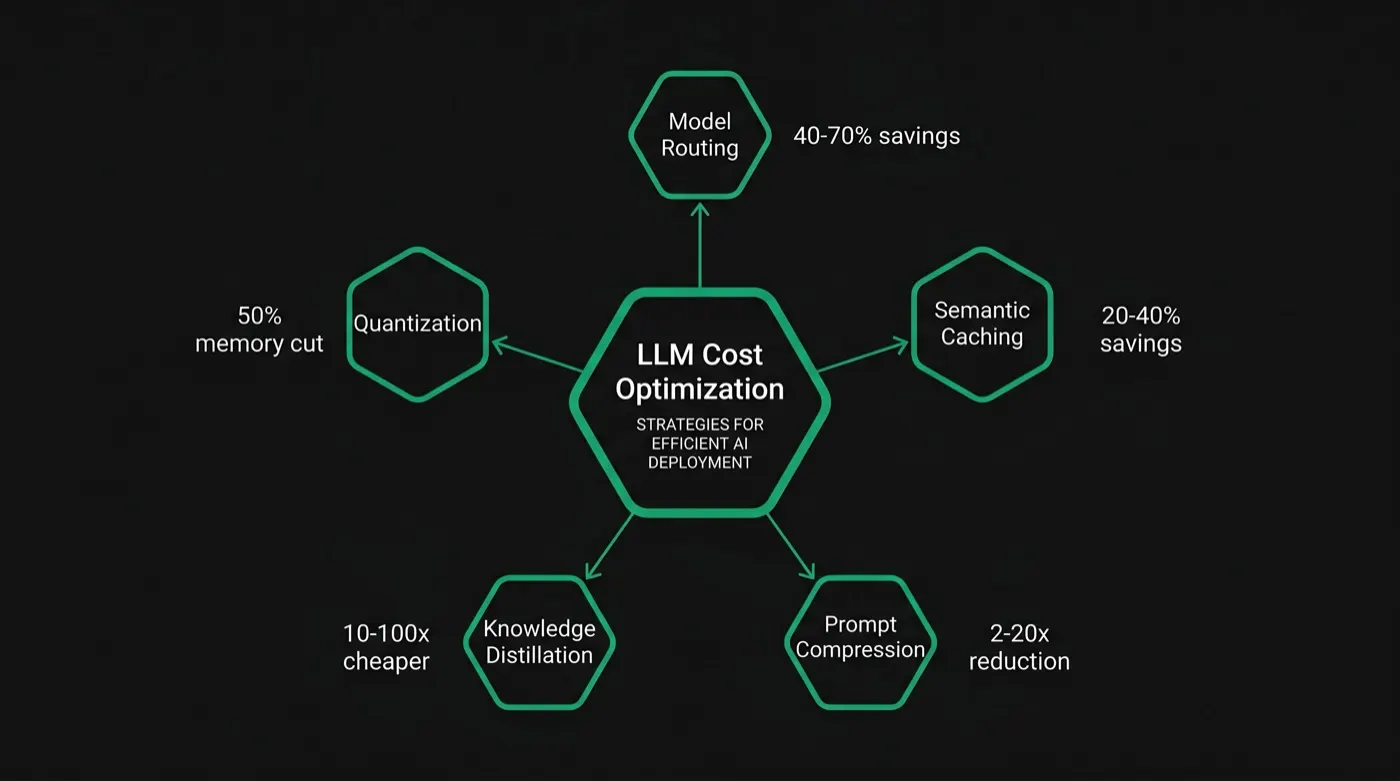
To reduce LLM costs without sacrificing quality, apply these five techniques in order of implementation complexity:
- Model routing — Direct each query to the cheapest model capable of handling it. Saves 40–70% on high-volume pipelines. (Deep dive →)
- Semantic caching — Reuse responses for semantically equivalent queries. Saves 20–40% on repetitive workloads with no additional API calls.
- Prompt compression — Remove redundant tokens from inputs before they reach the model. Achieves 2–20× compression with under 2% quality degradation. (Deep dive →)
- Knowledge distillation — Train a compact model on your specific task distribution using a frontier model as teacher. Highest ROI for stable, high-volume tasks.
- Quantization — Reduce model weight precision for self-hosted deployments. Cuts memory and compute without retraining.
Applied together, these techniques reduce enterprise LLM spend by 50–90% in production. The sections below explain the problem in depth, cover each technique with the supporting research, and compare tools.
The Overspending Problem
Most engineering teams don't choose their LLM based on task requirements. They choose it based on what they're already using. The path of least resistance is to use one model for everything — whatever produces the best output on the hardest task in the pipeline gets used on all tasks.
This creates a structural overspend problem. Consider a typical enterprise AI pipeline:
- Intent classification — determine what the user wants (binary or N-way classification)
- Entity extraction — pull structured fields from unstructured text
- Document summarization — condense long documents to key points
- Response generation — produce the final user-facing output
The first three tasks don't need GPT-4. A 7B or 13B fine-tuned model handles them at equal quality on most workloads — for 25–100x less per token. Only the last task, where quality variance matters most to users, benefits from frontier intelligence.
Routing every call through a single frontier model means paying frontier prices for commodity inference. That's the waste.
The scale of the problem is now substantial. Enterprise LLM API spending doubled in six months — from $3.5B in late 2024 to $8.4B by mid-2025 — with Menlo Ventures projecting $15B by 2026. Forty percent of enterprises now spend over $250K annually on LLMs. And research shows 60–80% of those costs come from just 20–30% of use cases — concentrated in high-volume, low-complexity tasks that a cheaper model could handle identically.
Why Engineers Default to Frontier Models
The overspend isn't irrational. There are real reasons teams don't optimize proactively:
Evaluation is hard. To know whether a smaller model is "good enough," you need to know what "good enough" means for each task — which requires building evals, collecting representative data, and running comparisons. Most teams skip this because it's engineering overhead that doesn't ship product features.
The cost is invisible until it isn't. At early scale, LLM spend is negligible. The problem becomes visible when you're at $10K/month, and by then the patterns are established and hard to change without touching production code.
Risk asymmetry. A quality regression caused by switching models is visible and blamed on the engineer who made the change. A 3x higher-than-necessary cost is invisible and blamed on "AI being expensive." The incentives favor over-modeling.
"Teams don't pay frontier prices because they need frontier quality on every call. They pay frontier prices because figuring out what each call actually needs is expensive — until someone automates it."
Five Techniques That Cut LLM Costs Without Sacrificing Quality
The academic literature on LLM efficiency has converged on five high-leverage techniques. Each targets a different source of waste.
Model Routing
Route each query to the cheapest model capable of handling it. Simple, high-confidence queries go to smaller models; complex, ambiguous, or high-stakes queries escalate to frontier models. The router itself is a lightweight classifier — trained on your own query distribution.
RouteLLM (Murray et al., 2024) demonstrates 2× cost reduction while maintaining 95% of GPT-4 quality. arxiv:2406.18665 ↗
Semantic Caching
Skip the API call entirely when a semantically equivalent query has been answered before. Unlike exact-match caching, semantic caching uses embedding similarity to match queries that ask the same thing in different words — recovering responses at near-zero cost.
Research on production LLM deployments shows 31% of queries are near-duplicates. Semantic caching achieves 40–67% cache hit rates (vs 8–12% for exact-match) and reduces API calls by up to 68.8%. arxiv:2403.02694 ↗
Knowledge Distillation
Train a small, task-specific model to match the outputs of a large one on your specific workload. The frontier model acts as a teacher; the distilled model learns to replicate its behavior on the narrow task distribution you actually run in production — at a fraction of the inference cost.
Distilling Step-by-Step (Hsieh et al., 2023) shows a 770M-parameter model can match a 540B-parameter PaLM on several benchmarks when trained on frontier model reasoning chains. arxiv:2212.10560 ↗
Prompt Compression
Reduce token count without reducing output quality. Long system prompts, verbose few-shot examples, and redundant context are compressed or restructured to contain the same semantic information in fewer tokens. The model produces identical outputs; you pay for fewer input tokens.
LLMLingua (Jiang et al., 2023) achieves up to 20× compression ratios with minimal quality loss on downstream tasks. arxiv:2310.05736 ↗
Quantization & KV Cache Compression
Reduce the numerical precision of model weights (quantization) and compress the key-value cache used during inference (KV compression) to cut memory requirements and increase throughput without retraining. Most effective for self-hosted open-source deployments.
SnapKV (Li et al., 2024) reduces KV cache memory by 8.2× while preserving output quality across long-context tasks. arxiv:2404.14469 ↗
Production Results: What Companies Are Actually Saving
These techniques aren't lab results. Teams running them in production report savings that match or exceed the research benchmarks — on real workloads, at scale.
What the Research Shows
The production results above are backed by peer-reviewed research demonstrating double-digit to 2-order-of-magnitude cost reductions:
The FrugalGPT result deserves special attention: a cascade strategy — routing first to cheap models and escalating only on low-confidence predictions — achieves 98% cost reduction while matching GPT-4 performance. The same quality. 50× lower cost. That's not a marginal improvement; it's a structural one.
Comparing LLM Cost Optimization Tools
The market has fragmented into specialized tools, each addressing a slice of the optimization problem. Here's how the major players map to the techniques above:
| Tool | Model Routing | Caching | Observability | Auto-Optimize | OSS |
|---|---|---|---|---|---|
| LeanLM | ✓ | ✓ | ✓ | ✓ | — |
| LiteLLM | ✓ | ✓ | ✓ | — | ✓ |
| Portkey | ✓ | ✓ | ✓ | — | — |
| OpenRouter | ✓ | — | — | — | — |
| Martian | ✓ | — | — | — | — |
| Not Diamond | ✓ | — | — | — | — |
| TensorZero | ✓ | — | ✓ | Partial | ✓ |
| Helicone | — | — | ✓ | — | ✓ |
| Langfuse | — | — | ✓ | — | ✓ |
| Braintrust | — | — | ✓ | — | ✓ |
Auto-Optimize = automated model selection, replacement training, or distillation — not just manual routing configuration. ✓ partial = requires manual setup per use case. As of February 2026.
Most tools handle one dimension well: routing, or observability, or caching. The gap in the market is end-to-end automation — profiling your workload, applying the right technique for each task, training replacements where necessary, and validating quality before any swap goes live.
The Validation Problem
Every optimization technique works on benchmarks. The hard part is knowing whether it works on your workload.
MMLU, HumanEval, and other standard benchmarks measure generic capability across a wide distribution of tasks. Your production queries are not that distribution. Your users ask the same 200 things 80% of the time. Your pipeline has specific output formats, specific edge cases, specific failure modes that no benchmark was designed to catch.
This is why optimization stalls. Engineering teams can reduce cost by 50% on benchmarks and still not ship the change, because they can't prove it holds on production data. Without that proof, the risk is too high to accept.
Solving the validation problem is what unlocks the savings. If you can run any candidate model against your actual production traffic — your queries, your expected outputs, your quality criteria — and get a pass/fail verdict, the optimization decision becomes mechanical. It either passes or it doesn't.
How LeanLM Approaches This
LeanLM is built around the validation-first approach. The workflow:
- Profile your LLM calls — connect via a one-line SDK change; LeanLM observes every call and classifies tasks by type, complexity, and optimization potential
- Identify candidates — surface the calls where the cost-to-quality ratio is worst: high volume, low complexity, expensive model
- Build replacements — apply routing, caching, distillation, or compression based on what each task needs
- Validate on your data — run the replacement against your actual production queries and outputs before any swap goes live
- Deploy incrementally — only move traffic to the optimized path once it passes your quality threshold
The result: savings are captured as soon as they're validated. The original model stays for anything the replacement can't handle. No quality regression ships.